LangChain
- icon: blog
name: LangChain
desc: langchain 官方
link: https://www.langchain.com/
target: _blank
- icon: blog
name: LangChain Docs
desc: langchain 官方
link: https://docs.langchain.com/
target: _blank架构体系
LangChain 并不仅仅是一个框架,而是一整个智能体开发平台,包含很多不同的组件。
其中,包含一系列开源的智能体(Agent)开发框架,而且兼容 Python 和 TypeScript 两种语言:
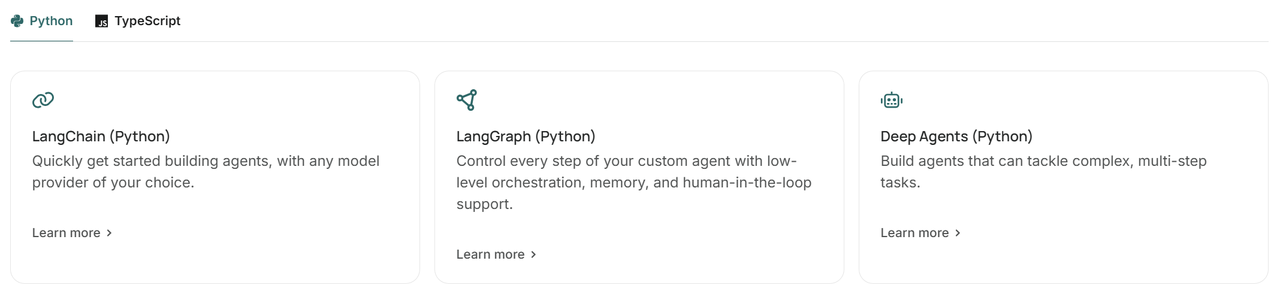
LangChain:用于快速构建智能体,可兼容任何模型提供商
LangGraph:从底层一步步控制智能体的构建,包括记忆(Memory)、人机协同(HITL)等
Deep Agents:用于构建复杂的、处理多步骤的任务的智能体
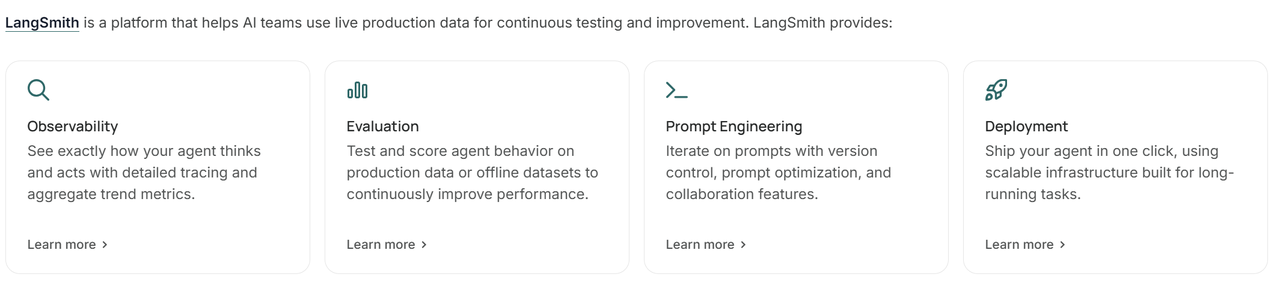
另外,LangChain 还包含一套帮助人工智能团队利用实时生产数据进行持续测试和改进的平台,叫做 LangSmith:
什么是 Agent
在人工智能领域,Agent是指一种能够感知环境、进行推理、自主决策并采取行动以实现特定目标的智能系统。
| 特性 | 传统聊天机器人/LLM | AI Agent |
|---|---|---|
| 交互模式 | 被动响应,问一句答一句 | 主动规划,以目标为导向 |
| 执行力 | 停留在文本生成层面 | 能操作软件、发送邮件、分析数据 |
| 自主性 | 需要人类给出详细步骤 | 只需给定最终目标,自主寻找路径 |
如果说大模型(LLM)是“大脑”,那么 Agent 就是“拥有手脚和思维逻辑的独立个体”。它不再只是被动地回答问题,而是能主动拆解任务并调用各种工具来完成工作。
当然,Agent的模式也是在不断演进的:
- 阶段一:ReAct + Tool Calling
- 阶段二:Reflection + Long Memory
- 阶段三:Multi Agent System,MAS
核心组件
Agent
代码示例:
# 1.加载环境变量
from dotenv import load_dotenv
load_dotenv()
# 2.定义工具,基础版,通过注释描述工具
@tool
def getWeather(location: str) -> str:
"""
Get the weather in a given location.
Args:
location: city name or coordinates
"""
return f"Current weather in {location} is sunny"
# 3.定义Agent
agent = create_agent(
"deepseek-chat", # 模型名称(必须是LangChain支持的模型)
tools=[getWeather] # 工具集
)
# 4.调用模型
print("🚀 正在调用大模型...")
response = agent.invoke({
"messages": [
{"role": "user", "content": "杭州今天天气如何?"}
]
})
# 5.打印结果
print(response)DEEPSEEK_API_KEY=sk-2c775c4708274b2ab2397c5f11xxxee4基本步骤
1.加载环境变量
2.定义工具
3.定义Agent
4.调用Agent
Langchain 提供了 create_agent 方法用来快速创建 Agent,我们只需要提供好 Agent 所需的模型(Models)、工具(Tools)即可。
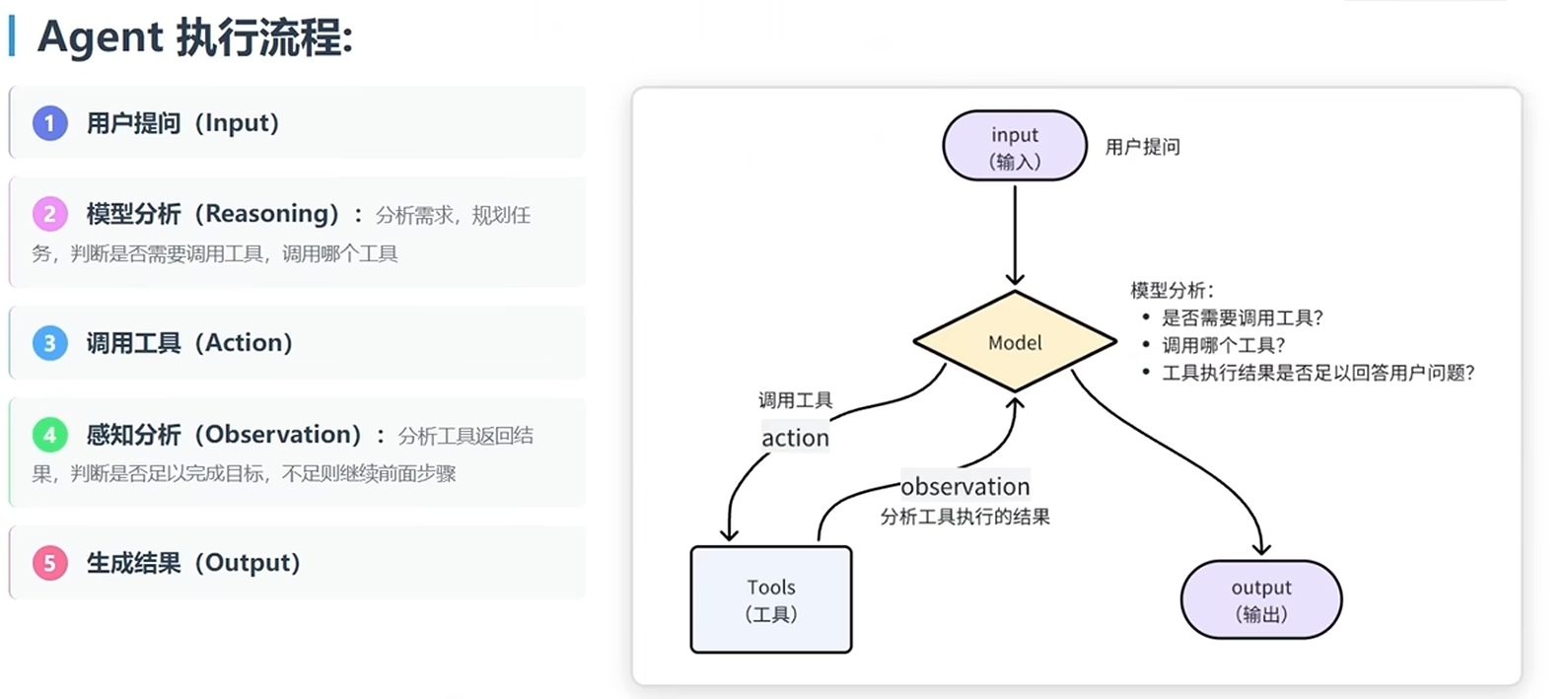
大模型提供的 API 接口中,有一个 tools 参数,描述了工具的详细信息:

所以,LangChain 会帮助我们把 tool 的信息封装为此 tool 参数,与 message 一起发送给大模型,大模型就了解 tool 的详细信息,根据用户需求判断是否需要调用 tool,需要调用哪个 tool。
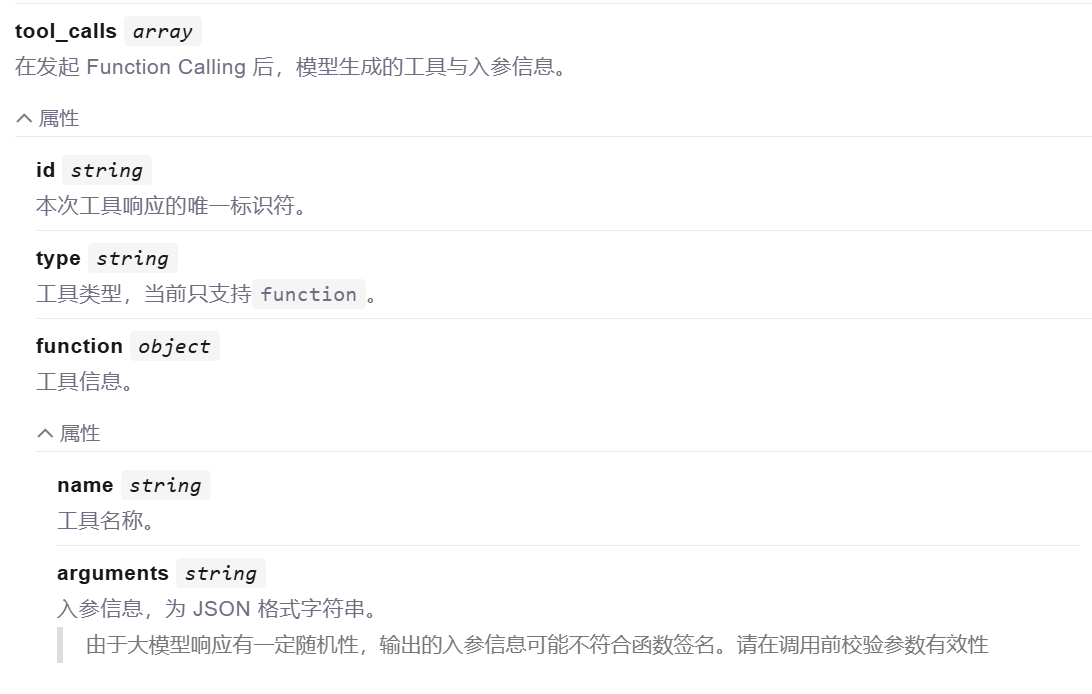
模型不能直接调用 tool,只能返回字符串。但是它可以把要调用的 tool信息、参数信息都以 Json 格式返回:
这样一来,LangChain 就会帮我们解析响应结果中的 Function 信息,也就是 tool 信息,就知道了要调用哪个函数,以及参数是什么了。LangChain 就会执行该函数,再把得到的结果再次发送给大模型。
具体的工作流程如图:
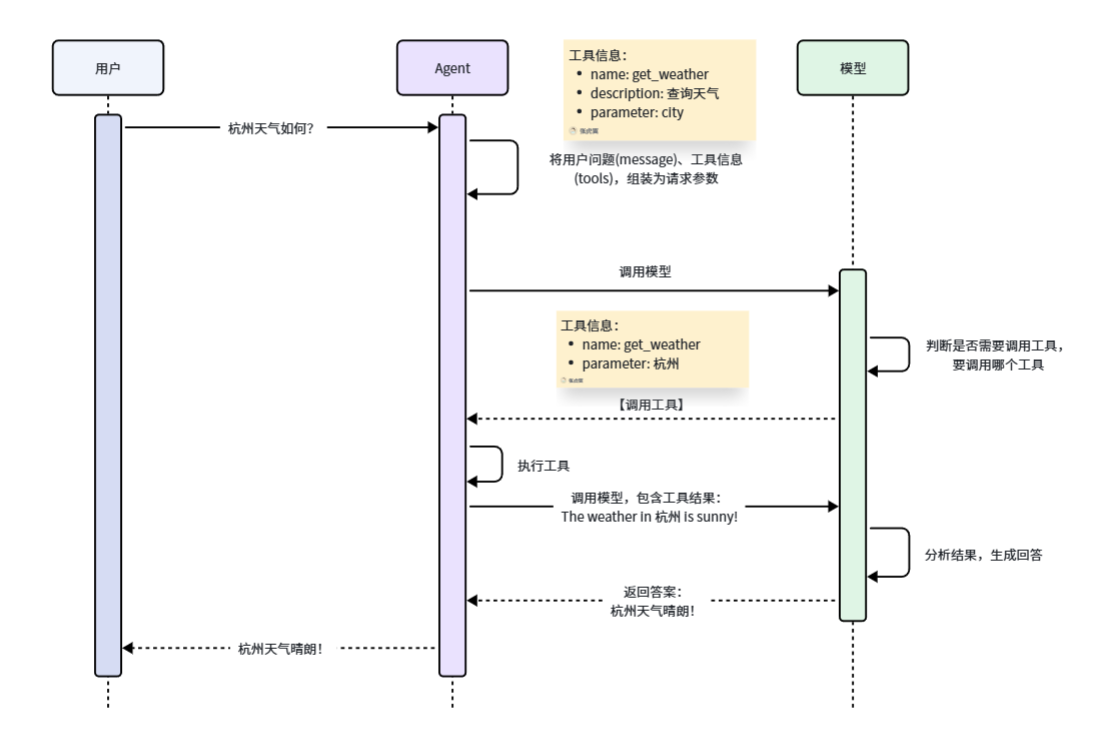
Models
这里说的模型,完整叫法是大语言模型(LLM)。它能够理解人类语言,使用人类语言生成内容、翻译、提取摘要、回答问题等。
不仅如此,现在大多数的模型还有一些特别能力:
(1)Tool calling - 调用外部工具(例如查询数据库或调用 API),并在其回复中使用这些工具返回的结果。
(2)Structured output - 将模型的响应结果约束为遵循已定义的格式,例如:json
(3)Multimodality - 可以处理和返回文本以外的数据,如图像、音频和视频。
(4)Reasoning - 模型可以执行多步推理来得出结论。
可以说 LLM 就是 Agent 的大脑,是 Agent 的推理引擎。它驱动 Agent 做出每个决定:何时调用工具、调用哪个工具、如何解释结果,以及何时提供最终答案。
LangChain 支持现在市面上大部分的大语言模型(LLM),并且提供了统一的模型调用接口。使您可以轻松访问许多不同的模型提供者,并且在模型之间进行试验和切换也变得很容易。
初始化模型
init_chat_model
# 导入Langchain的初始化模型的函数
from langchain.chat_models import init_chat_model
# 加载环境变量
from dotenv import load_dotenv
load_dotenv()
# 调用init_chat_model函数初始化模型,参数model用来指定模型名称
model = init_chat_model(model="deepseek-chat")提示
采用init_chat_model自动初始化模型时,模型的类型由 LangChain 通过模型名称自动推断。如果要切换其它模型,我们只需要安装其他模型依赖,然后配置 API_KEY 改变模型名称即可,其他的代码都不用。
init_chat_model默认会根据模型名称自动确定模型的提供者、其 base_url,并从 env 读取 api_key ,但前提是必须是langchain 支持的模型提供者。如果是其他不支持的模型,我们必须自定义模型参数来访问。
# 初始化模型
model = init_chat_model(
model="qwen-max", # 模型名称,这里可以自定义
model_provider="openai", # 如果是Langchain不支持的模型,需要指定模型提供者
base_url=os.getenv("DASHSCOPE_BASE_URL"),
api_key=os.getenv("DASHSCOPE_API_KEY")
)可见,通过参数自定义模型时,模型的类型由model_provider参数类决定。
除了修改模型提供者以外,init_chat_model方法允许我们调整模型参数,例如:temperature: 控制生成文本的随机性,值越小越确定,值越大越随机max_tokens: 控制生成文本的最大长度top_p: 控制生成文本的多样性,值越小越多样,值越大越确定timeout: 控制生成文本的超时时间max_retries: 控制生成文本的最大重试次数
使用Model类
init_chat_model 方法底层就是帮我们利用 Model 类创建对象。但只支持有限的模型,而在其社区,除了官方提供的Model,还有一些类是社区提供。具体支持的模型,可以查看官网。
例如使用社区版本的 Model 类来访问阿里云百炼的通义千问模型:
(1)安装依赖
# 社区依赖
uv add langchain-community
# 阿里云百炼依赖
uv add dashscope(2)使用
from langchain_community.chat_models.tongyi import ChatTongyi
# 使用Model类初始化模型
model = ChatTongyi(
model="qwen-plus"
# 其它模型参数...
)